
GPU games heat up just as AI Diffusion Framework looms
Chinese firms awash in compute options, as confusion remains on diffusion and whether export controls are "working"


The issue of whether Chinese AI developers will be able to keep up with Western AI companies in terms of innovating frontier AI models met with a stiff dose of reality over the past few weeks. It turns out the availability of advanced GPUs and AI optimized ASICs to leading Chinese firms from a variety of quarters is greater than most people thought.
At the same time, there appears to still be considerable pushback on the US government so-called AI Diffusion Framework, set to take effect officially on May 15. The Framework is under review, and its effective date could be pushed out 60 or more days to allow for full review and potential changes that have been proposed.
In this post we will look at these two trends and what they mean for China’s AI sector.
Are Chinese AI firms currently struggling to access GPUs? Evidently not
On the verge of the release of new models from DeepSeek, and with the continued rollout of other advanced Chinese AI models producing benchmark results on par with leading Western models, more than two years of US government-driven efforts to “throw sand into the wheels” of China’s AI development have had only marginal impact on the availability of advanced GPUs in China.
While getting a clearer sense of just how many of each type of AI-optimized semiconductor or cluster are in use remains complicated, the trend lines are more clear:
First, Chinese firms will continue to have access to GPUs from Nvidia for some time, including via remote access through the cloud.
Second, Chinese AI developers for some time will be in a transition period from dependence on Nvidia and its ecosystem, towards full adoption of a capable and expanding alternative AI stack centered on Huawei products.
Third, the Chinese government is now fully behind the indigenization push in the AI domain, but will continue to support a range of hybrid approaches that Chinese AI developers will pursue. Huawei will be a key player here.
Xi Jinping during a Politburo Study Session stressed that in order to seize the initiative and gain an advantage in the field of artificial intelligence, breakthroughs must be made in basic theories, methods, tools, etc. China must continue to strengthen basic research, concentrate on conquering core technologies such as high-end chips and basic software, and build an independent, controllable, and collaborative artificial intelligence basic software and hardware system. Use artificial intelligence to lead the paradigm shift in scientific research and accelerate scientific and technological innovation breakthroughs in various fields.

At the center of the discussion on GPUs are major AI developers such as Bytedance. The social media giant in 2024 stockpiled a large number of western GPUs from Nvidia, likely mostly H20s, and reportedly has a complement of around 1 million GPUs total, on par with western leaders such as Google, Meta, xAI, OpenAI, and Anthropic.
A recent report in Caijin, a leading Chinese economic media outlet, suggested that Bytedance had purchased around 100,000 GPUs in 2024 and been involved in selling some of its H20 GPUs to other players, including Alibaba and Tencent. The report generated a lot of discussions in the China GPU watcher community, and after extensive efforts to track down the veracity of the claims in this report, my sense is that it is not accurate in the details. The issue highlights the complexity of the GPU issue in China, which I have previously touched on in these spaces. Over the past three years, Chinese firms and their US suppliers Nvidia, AMD, and Intel have faced a complex regulatory situation. Changing performance and licensing requirements, and legal workarounds and workarounds that may suddenly become illegal, have all been introduced by US export control officials, often without accounting for the complexity of real world sales channels, supply chains, and business models.
Finally, as we were going to press, there were some indications that Nvidia has signaled to Chinese customers that there would be a new GPU coming that would be compliant with US export controls—the third time Nvidia would have redesigned a GPU specifically for the China market, an unprecedented burden on a company that has already lost tens of billions in revenue for GPUs that are far from the cutting edge models originally targeted by US controls. The Commerce Department has not yet issued a new rule to cover the “is informed” letter Nvidia received on April 9, so Nvidia has apparently told potential customers that the new design will require approval from Commerce. This puts the onus on US export control officials to justify the controls on the H20 and explain what the new performance criteria will be. With key experienced personnel fired from the export control arm of Commerce, and Nvidia demonstrating the ability to design around any new parameters, the outcome here remains unclear, particularly with domestic alternatives now more readily available.
The issue of access to advanced GPUs for Chinese companies outside of China also remains complex and rapidly evolving. A recent report suggested CoreWeave competitor Nscale was seeking a large contract with Bytedance that could provide access to GB200s in Nscale data centers outside China, in this case in Norway. Bytedance has also pushed back on the details of this story. Recently the Information reported in December that ByteDance has told suppliers it planned to spend up to $7 billion to access Nvidia chips in 2025, citing unnamed sources; this could mean a combination of advanced compute clusters both inside and outside China, and both Nvidia and Huawei hardware. Chinese companies involved in these arrangements are obviously not eager to publicize efforts, even if there are no legal restrictions, given the sensitivity of the issue and the desire to avoid attracting US government scrutiny. But the Nscale deal, and other similar arrangements being pursued by Chinese AI developers, highlight the difficulty US government efforts to control global access to advanced compute will face.

While big established companies with differing AI computing requirements have had to navigate this complexity, each has taken a different approach, attempting to stay clear of violations of changing US export controls while acquiring sufficient GPUs to meet their business development needs. This process has occurred within an increasingly complex geopolitical environment, tightening US export controls and bilateral tensions, and likely disinformation efforts coming from some quarters designed to confuse the issue and spur policy action—for example, still unproven accusations that DeepSeek has had access to tens of thousands of US controlled GPUs such as the H100s, in the face of unbiased industry analysis and complete lack of evidence that this is the case.

Separating the wheat from the chaff on domestic GPU availability
Recent reports indicate Huawei is close to providing samples of its Ascent 910D processor/GPU to Chinese AI developers and other customers. It remains unclear how the 910D will be packaged, despite some reports that there would be a new package that would include four processor dies packaged with high-bandwidth memory (HBM3), probably from Samsung. Some sources indicate that volume production of the 910D will not happen until Q3 in 2025, as the N6 process at the domestic foundry leader was completed in December 2024. The complication is that both the Ascend and Huawei’s Kirin ASIC for smartphones are competing for the limited advanced node process capacity at SMIC, though it appears that priority is being given to production of the Ascend, particularly in the wake of new US controls on the H20 and other US GPUs.
Complicating understanding how Huawei will package and position the new 910D is that the new die will be much more compute dense than the 910C, and there is also the Ascend 920 in the mix. Some reports suggest that the 920/910D will be a single die capable of supporting 900 TFLOPS of compute. Here the notional 920C will almost certainly be two 910D/920 dies packaged together to reach 1800 TFLOPS, similar to the 910C packaging.
In addition, the 910D will support HCCS (Huawei Compute Communication System) 4.0, Huawei’s proprietary high-speed interconnect technology designed specifically for efficiently connecting multiple Ascend AI chips or processors into larger clusters—version 4.0 will support 100,000 GPU clusters. It provides a robust communication backbone to facilitate massive parallel processing capabilities, essential for large-scale AI model training, inference, and high-performance computing (HPC) tasks.1
Huawei appears to want to position the 910D as more capable than the H100 and a direct competitor to the H200, though not on par with the H200 in a direct performance comparison. As I noted in a treatment last year of the status of China’s overall semiconductor industry as industrial planners and key private sector companies respond to US export controls, direct comparisons of GPUs are no longer useful in understanding where Chinese companies are going on developing advanced compute capabilities.
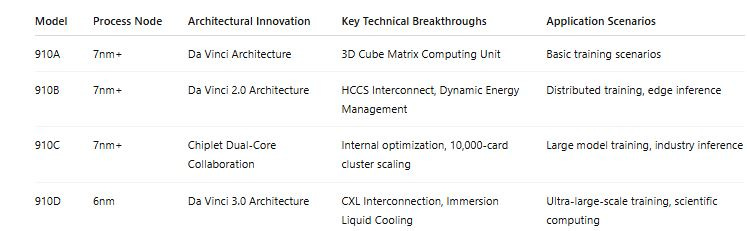
Huawei’s progress in developing AI-optimized software is a critical part of the story here. For instance, Huawei claims to have developed a tool for one-click conversion of CUDA to Compute Architecture for Neural Networks (CANN) code. along with Pytorch integration that is over 95 percent effective.2 In addition, Huawei’s Mindspore 2.6 supports Mixture of Experts (MoE). Now that Huawei has shown it can develop an entire complex software architecture such as the HarmonyOS for mobile devices, it will be turning its software developers more towards the AI stack. This, coupled with Huawei’s considerable expertise in advanced networking and soon silicon photonics, highlights what will be the increasing difficulty of making comparisons of advanced compute capabilities based on GPU-to-GPU performance claims.
Example use cases for 910D based systems in China (unconfirmed):
1. Supercomputing Center: a 910D cluster is planned for the National Supercomputing Center in Shenzhen to support the “Jiuzhang-4” quantum computing simulation.
2. Biomedicine: Biotech major BGI will be use a 910D cluster to predict protein structures and accelerate the new drug development cycle.
3. Autonomous driving: Baidu Apollo plans to use an Ascend 910D-based system to build a city-level simulation training platform.
Indeed, comparisons of individual GPUs between US and Chinese producers are no longer useful in gauging where China stands in terms of access to advanced compute from domestic sources. The Huawei CloudMatrix 384 for example is now being marketed by Huawei as a direct competitor for the Nvidia GB200 NVL2 cluster; comparisons here hinge on overall computing power and energy use, but these are also not the whole story, as Chinese companies will be acquiring different numbers of such clusters, including the next generation of the CloudMatrix series based on the Ascend 910D, for example. It will take some real-world examples of advanced AI models developed on top of these systems to determine where Chinese company development of frontier models stands in comparison to US leader such as OpenAI, Anthropic, Google, and Meta. We are already in a bifurcated AI stack world, where Chinese firms clearly have continued access to capable AI-optimized hardware, Huawei has a viable roadmap to continue to improve performance, and Chinese AI firms are pursuing software optimizations and transitioning to a full domestic AI stack based on Huawei tools such as Mindspore and CANN.
Finally, the link to Huawei’s apparent success in moving almost miraculously rapidly to developing a full AI solution for domestic Chinese clients is that Huawei’s vast experience tackling global markets means that, over time, Huawei hardware and software (coupled with advanced Chinese AI models from DeepSeek, Alibaba, Tencent, Bytedance, Baidu, Zhipu, Moonshot, and others) will provide formidable competition globally. (This is, ironically, the argument some are using to role back the AI Diffusion Rule.) For a superb and nuanced treatment of this issue, see a great post by investor and sometime collaborator Kevin Xu here. Kevin is one of the few China technology commentators who really gets the policy, technology, and the commercial games at play around AI and semiconductors, without the typical spin prevalent within the Beltway. We provided comments on these issue in a Sinica podcast with Kaiser Kuo last year and are due for another update.
More confusion around AI Diffusion coming
There is more speculation around the AI Diffusion Framework as the May 15 deadline for official entry into force approaches. First, it is necessary to highlight some of the assumptions underlying the development of the framework.
Foremost among these is the idea of diversion. US officials, as noted previously in this Substack, have launched investigations into potential diversion of advanced GPUs via Singapore to other destinations in Asia. A close examination of this issue reveals that, in terms of preventing large clusters of advanced GPUs from reaching Chinese end users, the concern around diversion is really a non-issue, and just another of many attempts to change or enlarge the goalposts of US policy on advanced compute.
Here, there is no evidence of any sizeable “diversion” of GPUs to companies in China that are actually developing AI models. The most infamous claim of diversion appears to be the allegations leveled at DeepSeek, that the firm somehow has access to 50,000 H100 GPUs. As I have noted, there is no evidence of this, and as seasoned industry observers know, a cluster of that size cannot be either hidden easily or operated without support from Nvidia.
As noted in a previous post, the furor over GPU shipments to Singapore proved to be another red herring, as no evidence has surfaced that GPUs are being “diverted” via Singapore, which serves as a financial and logistics hub for paperwork related to GPU server shipments in the region.
In any case, leading Chinese firms developing frontier AI models have deliberately avoided acquiring GPUs that are export controlled to China and may have been “diverted.” These firms are eager to avoid running afoul of US export control laws, and are very careful about which GPUs they use for training.
Nvidia last week pushed back on claims by Anthropic that GPUs have been diverted in novel ways, noting that “American firms should focus on innovation and rise to the challenge, rather than tell tall tales that large, heavy, and sensitive electronics are somehow smuggled in ‘baby bumps’ or ‘alongside live lobsters.’” The back and forth here is instructive:
Nvidia spokesperson: “China, with half of the world’s AI researchers, has highly capable AI experts at every layer of the AI stack. America cannot manipulate regulators to capture victory in AI.”
Anthropic spokesperson: “Anthropic stands by its recently filed public submission in support of strong and balanced export controls that help secure America’s lead in infrastructure development and ensure that the values of freedom and democracy shape the future of AI.”
Second is the issue of the entire rationale for the AI Diffusion Framework, which is supposed to prevent Chinese companies developing advanced AI models from accessing controlled GPUs outside China. When the AI Diffusion Framework was being developed, there was no evidence that leading Chinese firms were interested in training advanced AI models remotely from China using overseas server clusters. In addition, if the goal of the overall policy is to prevent military end users from having access to advanced compute to train models, it seems highly improbable that military or security services or state-backed cyber operators training or doing research on advanced AI models would be allowed to use advanced compute hardware outside of China to do this. As a long-time analyst of China’s defense industrial complex and military command and control systems told me, this approach is inconceivable to anyone who studies these Chinese organizations and their security practices.
Nevertheless, as of early May, the ongoing review of the AI Diffusion Framework is likely to mean that the entry into force could be put off via a 60-day extension of the May 15 deadline. As of early May, it appeared that US officials at the Commerce Department were considering a number of changes to the AI Diffusion Framework, based on both some industry input, and preferences coming from industry, which were advocating for both tightening and loosening of the rule’s provisions:
There is consideration of removing country caps and tiered system and going to bilateral agreements coupled with a global licensing regime, which would likely act as a de facto cap for some countries.
Lowering the exemption threshold from 1700 to 500 H100 GPU equivalents.
Unlike during the Biden administration, when the drafting of rules such as this were typically limited to a small group of officials at the White House—often with no industry input—this time around it is likely that other bureaucratic players are involved, including possibly OSPT Director Michael Kratsios and AI and Crypto Czar David Sacks and their staff.
For the AI Diffusion Framework, it is likely that the original rule will be replaced by a new draft, with considerable changes, though Commerce will not necessarily treat this as a completely new rule requiring a new comment period; it could be issued and intended to take effect immediately. However, if there are new provisions that require time for companies to resource and implement, this would likely require a new extension of the entry-into-force date, which seems likely. While US allies including Poland, Israel, and others are strongly opposed to the tiering system, if it is removed there will still be a licensing requirement, with a default presumption of denial. In the original rule, the high thresholds for requiring a license, plus the (national and universal) validated end user structure, and the Tier 1 category were collectively intended to reduce the requirement for a licensing process, with the assumption of a bilateral agreement around VEU status.
In addition, mid-April some US lawmakers were pushing for the Rule to be pulled back entirely. The letter, signed by Senators Pete Ricketts, Tommy Tuberville and Thom Tillis, Markwayne Mullin, Ted Budd, Roger Wicker, and Eric Schmitt, made points similar to what industry veterans have said around the Rule: it will restrict the spread of US technology and open opportunities for alternatives, specifically Huawei.
“Every day this rule remains in place, American companies face mounting uncertainty, stalled investments, and the risk of losing critical global partnerships that cannot be easily regained.”—Four US senators in letter to Commerce Department on AI Diffusion Framework
Are US export controls targeting advanced (and not-so-advanced) GPUs working?
This, of course, is the $5.5 billion question of the moment. There are now basically two camps: proponents of the export controls, who are now saying it may be as much as a decade before the full impact of the controls can be recognized (wow!), and a second camp which holds that the controls have basically failed and the costs of the controls are mounting—primarily to the US, but also to allied technology company leaders, most of them currently among the top ranks of firms in their respective sectors.
“China is not behind” in AI...China is right behind us. We are very close. Remember this is a long-term, infinite race.” Huawei is “one of the most formidable technology companies in the world.” —Nvidia CEO Jensen Huang
During testimony in front of the House Foreign Affairs Committee last week, Huang warned against measures such as the AI Diffusion Rule, which he and other industry leaders believe will undermine US technology leadership in this space by incentivizing countries and companies to turn to alternatives, namely Huawei.

The proponents of the export controls are working to continue to evolve the narrative that, in fact, the controls have been effective in slowing down the development of advanced AI models in China. The latest version being road tested is that DeepSeek is in fact an elaborate psyop by China to convince someone (who exactly?) that the export controls are not working. Under this narrative, the whole DeepSeek effort is an elaborate operation, replete with massive disinformation efforts, designed to hoodwink the uninitiated into believing that the controls are not working and China is developing models as capable as those of western competitors only be cheating and working around the controls (with hints about diversion thrown in of course). Buying into this theory requires deliberately ignoring what has happened in China’s AI sector over the past two years and the ample documentation on DeepSeek as a company and CEO Liang Wenfeng as an entrepreneur and investor. It also means believing that the open source/model weight community has been somehow misled by the volume of publicly available research released by DeepSeek, and accepting the existence of the “clandestine” 50,000 H100 cluster somewhere in Zhejiang Province. Ironically, the purported existence of this cluster in and of itself is required to demonstrate that the export controls are working, because without access to these restricted GPUs, the theory goes, DeepSeek would not have been capable of creating V3 and R1.
The growing “small gain, high cost” camp holds that, in addition to the high costs to US and allied companies and significant supply chain and business model disruptions, the controls have significantly propelled forward innovation and business model expansion in China, while unleashing the full technological capabilities of Huawei in particular. Some on the “export controls are working” side caricature these arguments as something like, “US government efforts to block advanced technologies being transferred to China are futile and do more harm to the US.” But the issue is really about implementing (or failing to implement) smart policies with clear goals that make sense to industry and allies and limit collateral damage.
As Huawei switches its focus, for example, from five years of building out the HarmonyOS cross platform mobile operating system from scratch, to developing software supporting AI development, including Mindspore, CANN, and other tools of the AI stack, the implications for both China’s domestic AI development and the ability of Chinese companies to export “AI in a box” (as Kevin Xu recently has called Huawei’s approach) become salient. As the savvy China tech policy observer Samm Sacks recently noted: “…the case of Huawei suggests sweeping trade restrictions are an ineffective policy that is fueling — not foiling — advances in China’s domestic technology in ways that could shift the global market.”
Bingo. As I noted in a recent commentary on Xi’s AI Politburo Study Session: for China on AI, it is clearly game on…..
Key Features of HCCS:
High-Speed, Low-Latency Communication
Designed to support ultra-fast data exchange between thousands of computing nodes.
Latency and synchronization overhead is significantly reduced, allowing efficient scaling of workloads across massive clusters.
Scalable Cluster Size
The latest version (HCCS 4.0 as referenced) supports interconnections for clusters of up to 100,000 AI accelerator cards.
Synchronization efficiency is ≥98%, meaning minimal overhead in maintaining synchronization among nodes.
Advanced Synchronization and Load Balancing
Optimized to handle distributed training of extremely large AI models, enabling efficient distribution of data, parameters, and computation across nodes.
Supports efficient load balancing, helping prevent bottlenecks and under-utilized resources.
Energy Efficiency and Thermal Management
Often used alongside advanced cooling solutions, such as immersion liquid cooling, to manage thermal issues associated with high-density compute clusters.
Use Cases and Applications:
Large AI Model Training:
Ideal for training massive deep learning models, like GPT-style large language models (e.g., DeepSeek-R1-671B).
Scientific and High-Performance Computing (HPC):
Suitable for applications requiring intensive parallel computation (quantum simulations, computational biology, drug discovery, climate modeling).
Real-Time Inference at Scale:
Allows deployment of large models for real-time applications such as large-scale autonomous driving simulation, smart city infrastructure, and intelligent manufacturing.
Comparison to Other Technologies:
NVIDIA NVLink/NVSwitch:
Similar conceptually, NVIDIA’s interconnect technology offers high bandwidth and low latency specifically optimized for GPU clusters.
AMD Infinity Fabric and Intel CXL:
HCCS shares similarities with technologies like AMD's Infinity Fabric and Intel’s Compute Express Link (CXL), focusing on high-speed, coherent memory and compute connectivity at scale.
However, Huawei's HCCS specifically targets the unique requirements of Huawei's Ascend chip ecosystem, emphasizing large-scale synchronization for AI workloads, very high scalability, and compatibility with proprietary Huawei frameworks like MindSpore and CANN.
Strategic Importance for Huawei:
HCCS is a key differentiator for Huawei’s Ascend AI infrastructure, crucial in China's AI ecosystem given export restrictions on advanced chips from NVIDIA and AMD.
Provides a domestic alternative to NVIDIA's ecosystem, critical for national-level AI infrastructure in China.
CANN 6.0 claims to support one-click migration of CUDA code, and compatibility of PyTorch framework of around 95% according to some sources.
CUDA Compatibility:
One-click migration of CUDA codes implies that Huawei's latest software stack, CANN 6.0 (Compute Architecture for Neural Networks), allows developers to directly convert or translate existing CUDA-based GPU code (originally written for NVIDIA hardware) into code compatible with Huawei's Ascend hardware.
Instead of manually rewriting CUDA kernels, developers can potentially migrate their models and algorithms more easily, significantly reducing time and resources needed for transitioning away from NVIDIA GPUs to Huawei Ascend chips.
PyTorch Compatibility (95%):
Achieving 95% compatibility with PyTorch means Huawei’s platform can run almost all PyTorch functionalities without extensive modifications.
It suggests that developers familiar with PyTorch can easily adapt their existing workflows, models, and training scripts to the Ascend platform, leveraging familiar APIs, model architectures, and training pipelines.
While this high level of compatibility covers most features, the remaining 5% could involve specialized functionalities, custom CUDA kernels, niche libraries, or advanced APIs not yet fully supported.
What this may mean":
Reduced Barrier to Adoption:
Simplifying migration encourages organizations dependent on NVIDIA GPUs (and CUDA) to experiment with or switch to Huawei’s Ascend processors.Ecosystem Expansion:
High PyTorch compatibility signals Huawei’s commitment to becoming a viable alternative to NVIDIA by providing robust software tools, encouraging broader adoption across industries.Geopolitical & Economic Motivation:
Given the current restrictions on NVIDIA GPU exports to China, Huawei’s strategy directly addresses a critical market need: maintaining the continuity of AI model development and deployment within China without significant workflow disruption.
What are the limitations here to consider:
Performance Optimization:
Even if CUDA codes migrate "one-click," performance parity with original CUDA code on NVIDIA GPUs isn't guaranteed. Optimization for Ascend hardware might still be necessary for peak efficiency.Full Feature Support:
95% PyTorch compatibility leaves room for some specialized tasks or newer features that may require extra effort or remain unsupported initially.
In summary, Huawei’s CANN 6.0 significantly simplifies transitioning from NVIDIA hardware and CUDA/PyTorch frameworks to Huawei’s own Ascend platform, potentially reshaping the competitive landscape by reducing technological friction for developers and enterprises, but moving developers off Nvidia’s ecosystem will not be easy, and much harder than the Android to HarmonyOS transition, which has taken 5 years and still faces challenges.
These deep dives are endlessly fascinating. Thanks so much for putting them out!