


Opening the vault: DeepSeek releases most (but not all) of its secrets
Most of the released optimizations were long in development and form an interconnected framework


During Open Source Week, China’s AI phenom DeepSeek did something unusual, releasing six separate posts/papers detailing key elements of its hardware and software optimizations. Observers are characterizing this as unprecedented levels of information release about an open source/weight model and how it was developed. This is an important part of #TheDeepSeekEffect. For more on the impact of DeepSeek on the open source community outside China, see here. Here are a few observations on the releases.
These are humble building blocks of our online service: documented, deployed and battle-tested in production. No vaporware, just sincere code that moved our tiny yet ambitious dream forward. —DeepSeek
Day 1: FlashMLA. FlashMLA is an efficient MLA decoding kernel for Hopper GPUs, optimized for variable-length sequences serving.
Significantly, for this release, DeepSeek included a page outlining “Community support”, which listed most of the major non-Huawei Chinese GPU developers. These are all small but capable players in the China GPU space, and all are providing support for running DeepSeek models on their GPUs.
For MetaX GPUs, visit the official website: MetaX. The corresponding FlashMLA version can be found at: MetaX-MACA/FlashMLA
For the Moore Threads GPU, visit the official website: Moore Threads. The corresponding FlashMLA version is available on GitHub: MooreThreads/MT-flashMLA.
For the Hygon DCU, visit the official website: Hygon Developer. The corresponding FlashMLA version is available here: OpenDAS/MLAttention.
For the Intellifusion NNP, visit the official website: Intellifusion. The corresponding FlashMLA version is available on Gitee: Intellifusion/tyllm.
For Iluvatar Corex GPUs, visit the official website: Iluvatar Corex. The corresponding FlashMLA version is available on GitHub: Deep-Spark/FlashMLA

Day 2: DeepEP. DeepEP is a communication library tailored for Mixture-of-Experts (MoE) and expert parallelism (EP). It provides high-throughput and low-latency all-to-all GPU kernels, which are also known as MoE dispatch and combine. The library also supports low-precision operations, including FP8.
Day 3: DeepGEMM. DeepGEMM is an FP8 GEMM library that supports both dense and MoE GEMMs, powering V3/R1 training and inference.
Day 4: DualPipe. Optimized Parallelism Strategies. DualPipe is a bidirectional pipeline parallelism algorithm for computation-communication overlap in V3/R1 training.
Day 5: 3FS. Fire-Flyer File System (3FS) is a parallel file system that utilizes the full bandwidth of modern SSDs and RDMA networks.
Day 6: Inference System Overview: This is a description of how DeepSeek overcame the complexities introduced by their Expert Parallelism (EP) approach, which significantly scales the batch size, enhancing GPU matrix computation efficiency and boosting throughput, and distributes experts across GPUs, with each GPU processing only a small subset of experts (reducing memory access demands), thereby lowering latency.
What does the open sourcing of much more than model weights signify?
As a whole, what do these releases by DeepSeek mean? They are all related to the optimization of the available hardware systems that DeepSeek has had access to over the past four years: a cluster of 10,000 Nvidia A100s and a smaller cluster of several thousands of export control modified Nvidia H800s. Much of what was released over Open Source Week was also detailed in an August 2024 paper by DeepSeek that few seem to have noticed: Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning.
One of the key elements of the overall DeepSeek approach is the new file system, details of which were released on Day 5. The file system is likely to be one of the more widely adopted elements of the DeepSeek approach, and goes way beyond just open sourcing model weights, for example. The 3FS system is a Linux-based parallel file system designed for use in AI-HPC operations. That DeepSeek would open source this is a significant development. (For more on 3FS, see this.) The four-year journey to get this point is truly impressive, particularly given the constraints imposed on High Flyer and DeepSeek by US export controls.

Interestingly, the DeepSeek team also thanks the HFAiLab System Team and the Operations Team. The HFAiLab (幻方AI or formally 幻方人工智能基础研究有限公司) is the research arm that was spun off as an “independent” unit of High Flyer Quant, and which put together the 10,000 A100 cluster which DeepSeek has been able to access, presumably when it is not being used to predict stock market futures. The exact relationship between the two and how costs are apportioned remain unclear. Many of the details released during Open Source Week appear to have been around for some time; since around 2020 on the High Flyer website or related websites.
While DeepSeek’s role in the Chinese model price war last summer does not appear to have been reported in western media, it was heavily covered in Chinese language media, after the release of DeepSeek V2 in early May 2024. The training and development of this model clearly leveraged many of the elements that DeepSeek focused on and had under development for a number of years prior.
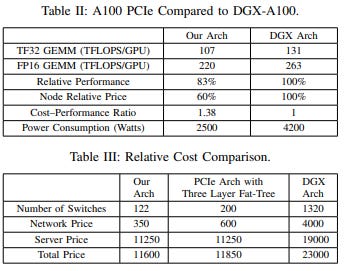
The Fire Flyer August 2024 release is an interesting paper, and shows where the focus of DeepSeek has been over the past two years, i.e., not on optimizing model training on the mythical set of “50K hoppers” to which some have alleged the firm has access. If they had had access to such a cluster, why would the focus of all the efforts DeepSeek documents in the paper and the Open Source Week releases have been on optimizing hardware use, GPU-to-GPU communications, CPU utilization, etc., while demonstrating a deep understanding of communications links including NVLink, Infiniband, and PCIe? As part of this effort, DeepSeek consulted with engineers from Nvidia and AMD, and even recommended to AMD some changes to improve performance! The answer seems pretty obvious, although I will eat my RTX 4090 if someone shows me the mythical hoppers. The closest DeepSeek is likely to get to 50K Hoppers is rumored provision by Huawei of 32K Ascend 910Cs, which according to some benchmarks can get to something like 60 percent of the raw performance of the H100—but with the addition of DeepSeek’s comms optimizations as outlined during Open Source Week, this could make up more of the difference.
A look at the sources used in the AI-HPC paper is revealing in understanding how DeepSeek engineers approached the challenges they faced:
Academic and industry references: The paper cites 101 sources, including a mix of academic papers, industry reports, and technical documentation. These sources span:
Foundational AI/ML papers (AI/ML co-founder Yann LeCun on deep learning, Ashish Vaswani on transformers)
HPC architecture papers (Charles Leiserson on Fat-Tree networks)
Technical documentation from Nvidia and other hardware vendors
Recent papers on large language models and AI systems
Self-citation: The authors reference their own previous work, particularly around the HAI Platform and DeepSeek AI models, indicating this paper builds on their established research.
Contemporary research: The paper includes references to very recent work (up to 2024) on large language models, including GPT-4, PaLM, and their own DeepSeek models—showing they’re engaging with the cutting edge of the field.
Hardware/software documentation: Many citations refer to technical specifications of hardware components (NVIDIA GPUs, Mellanox networking) and software libraries (NCCL, PyTorch).
Industry practices: The paper references industry systems from Meta, ByteDance, Alibaba, and Google, showing awareness of how commercial entities are building similar systems.
Comprehensive coverage: The bibliography covers all aspects of their system: hardware architecture, networking, software optimization, fault tolerance.
Empirical data: The paper includes substantial original data about hardware failures, performance benchmarks, and system characteristics.
Technical Depth: Citations support detailed technical claims about network topology, communication protocols, and performance characteristics.
All of this points to the depth the DeepSeek and HFAi Lab teams’ understanding of GPU hardware, GPU and memory storage system interconnectivity, software optimizations, and energy efficiency and costs. This understanding was developed over at least a five-year period of intense research and practical application on the hardware that High Flyer was able to assemble, and that few paid attention to until the release of DeepSeek V2 in May 2024.
The output of DeepSeek’s Open Source Week contributions goes far beyond mere open source/weight releases. As the open source world digests this new output, it will be critical to watch how DeepSeek’s innovations are taken up both by western open source and proprietary model developers and deployers, for training and perhaps more importantly for compute time scaling and inference. This is happening as the US government considers bans on all AI semiconductor exports to China, restrictions on DeepSeek’s smartphone app, and potentially a broader attempt to control the propagation of open source/weight models. But Pandora’s Box just became significantly harder to repackage.